

Neste quinto artigo sobre ferramentas de apoio a times DevOps, vamos nos aprofundar nas Resource Declarations do Puppet e subir alguns serviços como Apache, Ntp, além do tão esperado Docker, de maneira rápida e indolor.
Se você ainda não conhece o Puppet, dá uma lida nos artigos anteriores Puppet: Instalação e fundamentos – DevOps Parte 4 e Gerenciamento de configuração e automação de servidores – DevOps Parte 3.
Box do Vagrant Utilizada
No artigo anterior sobre Puppet já construímos e disponibilizamos a box eunati/debian-jessie64-puppet5 para o Vagrant com o Puppet 5 e seus principais módulos instalados. Essa é a box será utilizada em nossos exemplos.
Se você ainda não conhece o Vagrant (será utilizado aqui para gerenciar as máquinas virtuais), dê uma lida nos artigos Vagrant: Turbine suas VMs e ambientes de desenvolvimento – DevOps Parte 1 e Vagrant: Crie sua própria box e disponibilize-a na Vagrant Cloud – DevOps Parte 2.

Criando o Vagrantfile
Como exemplo inicial, vamos utilizar o Puppet para provisionar um servidor web Apache e depois um Ntp (sincronização de relógios).
Vamos criar o Vagrantfile (arquivo de configuração do Vagrant) para subir uma máquina virtual utilizando a box eunati/debian-jessie64-puppet5.
Dá uma olhada no conteúdo:
Observe que nesse Vagrantfile definimos o nome da máquina virtual (config.vm.host_name), mapeamos a porta 80 (Http) da máquina virtual (guest) para a 8080 do nosso host (config.vm.network), criamos uma pasta sincronizada entre a máquina virtal e o host (config.vm.synced_folder) para colocar nossos HTMLs e indicamos que o Vagrant deverá utilizar o Puppet para provisionamento (config.vm.provision).
Node definitions do Puppet
Na mesma pasta do Vagranfile, vamos criar uma pasta chamada manifests e dentro dela o arquivo default.pp. Conforme a documentação do Vagrant, por padrão, quando mandarmos o Vagrant utilizar o Puppet Apply para provisionamento, ele irá procurar por esse arquivo como ponto de entrada.
Diferentemente do nosso exemplo de instalação do pacote links no artigo anterior, vamos iniciar nosso default.pp com uma node definition (também chamada de node statement):
A node definition or node statement is a block of Puppet code that will only be included in matching nodes’ catalogs. This feature allows you to assign specific configurations to specific nodes. Unlike more general conditional structures, node statements only match nodes by name. By default, the name of a node is its certname (which defaults to the node’s fully qualified domain name).
Assim, com uma node definition conseguimos indicar se um trecho de código do Puppet será incluído ou não no catalogo de uma ou várias máquinas, apenas utilizando o nome das máquinas. No nosso Vagrantfile, definimos o nome da máquina virtual para desenvolvimento.eunati (máquina desenvolvimento, domínio eunati).
No nosso default.pp, para que a máquina desenvolvimento.eunati seja a máquina provisionada, começamos com:
De acordo com a documentação das node definitions, podemos utilizar vários nomes de máquinas ou expressões regulares em sua declaração. Ainda estamos usando o Puppet na arquitetura Standalone, mas começamos a entender como é possível gerenciar a configuração de um parque de servidores com o Puppet na arquitetura Agent/Master, né ?
Provisionando o Apache
Dentro da nossa node definition, vamos adicionar algumas resource declarations para subir nosso Apache (nas próximas postagens, vamos subir o Apache como container no Docker de maneira bem mais prática).
Já vimos que uma resource declaration é uma expressão que descreve o estado desejado de um resource (recurso) e possui o seguinte formato:
TYPE { 'TITLE':
<ATTRIBUTE> => <VALUE>,
<ATTRIBUTE> => <VALUE>,
}
Adicionar resource declarations em uma node definition não é uma boa prática de acordo com a documentação do Puppet (o ideal é adicionar apenas variáveis e utilização de classes), entretanto, por fins didáticos, vou iniciar dessa maneira e depois evoluiremos para as melhores práticas.
Segue a versão do default.pp que faz o provisionamento do Apache (existem maneiras bem mais concisas de fazer isso utilizando módulos e classes do Puppet, mas o intuito é que você compreenda como ele funciona):
Observe que adicionamos três resource declarations dentro da node definition da máquina desenvolvimento.eunati, uma para cada um dos resource types a seguir:
- exec = executa um comando externo. No código acima, utilizamos para fazer uma atualização do apt-get. Observe que essa resource declaration recebeu o título ‘update’;
- package = gerencia pacotes. No código acima, utilizamos para garantir que o pacote apache2 está instalado na máquina (ensure => installed). Você percebeu que nessa resource declaration não foi necessário indicar qual gerenciador de pacotes deveria ser utilizado para a instalação ? Isso pois o package já “tenta adivinhar” o gerenciador de pacotes, embora também seja possível indicar qual deve ser utilizado com o atributo provider.
- service = gerencia serviços em execução. No código acima, utilizamos para garantir que o serviço apache2 está rodando (ensure => running). No Gnu/Linux, existem várias soluções para inicialização dos serviços (upstart, sysvinit, systemd, openrc), e o service também abstrai isso pra gente.
Quando falei sobre gerenciamento de configuração de servidores, lembra quando eu falei sobre a idempotência ? As três resource declarations acima garantem a idempotência (o apt-get update também é idempotente).
Eu queria chamar a atenção para o atributo require que foi utilizado junto ao package e ao service. Ele garante que ao aplicar um resource declaration uma outra resource declaration já tenha sido aplicada. Assim, antes de instalar o pacote apache2, é necessário ter aplicado o Exec[‘update’] e antes de subir o serviço apache2 é necessário ter aplicado o Package[‘apache2’].
Antes de subir a máquina virtual, vamos criar na mesma pasta do Vagrantfile uma pasta chamada html (a ser compartilhada pelo Vagrant com a máquina) e adicionar um arquivo index.html com o texto “Hello World Apache + Puppet”.
Agora estamos prontos para subir a máquina com:
$ vagrant up
Observe a saída do Puppet no momento do provisionamento:
Agora, acesse a URL: http://localhost:8080/hello/
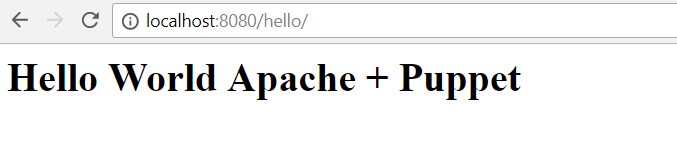
Hello World!
It works! Apache rodando e exibindo nosso html! Maravilhas.
Provisionando o Ntp
Agora, vamos fazer o provisionamento do Ntp utilizando o mesmo arquivo default.pp. Vamos fazer o provisionamento da maneira mais trabalhosa possível e adiante te mostrarei como deixar o código bem mais conciso.
O Vagrantfile pode permanecer idêntico ao que já criamos. Veja a nova versão do default.pp, já com as resource declarations necessárias para o correto provisionamento do Ntp e utilizando os servidores a.ntp.br e b.ntp.br:
Observe que agora temos alguns elementos novos no nosso arquivo:
- $file_ntp_config_file_path = Essa é uma variável que pode ser utilizada no seu manifest. No caso, apontamos para o caminho do arquivo de configuração do ntp;
- package ‘ntp’ = Garante que o pacote ntp está instalado;
- file ‘ntp_config_file’ = Garante que o arquivo de configuração do ntp existe. Observe que aqui já fazemos uso da variável $file_ntp_config_file_path ;
- exec ‘ntp_config’ = Executamos um comando para configurar o NTP. Utilizamos o sed para remover os servidores padrões que já vêm no arquivo do NTP e o echo para adicionar ao final do arquivo de configuração os servidores a.ntp.br e b.ntp.br. Observe que nessa resource declaration utilizamos o atributo unless. O unless é o responsável por garantir que essa resource declaration seja idempotente. Sem ele, caso o puppet apply fosse executado mais de uma vez, os servidores a.ntp.br e b.ntp.br seriam adicionados ao final do arquivo mais de uma vez. Com o unless, o exec só executará o command caso o arquivo ainda não possua a stinrg ntp.br em seu conteúdo.
- service ‘ntp’ = Garante que o serviço ntp está sendo executado. Observe o atributo subscribe. Com ele, garantimos que qualquer mudança no Exec[‘ntp_config’] forçara um restart no serviço ntp, já obtendo as novas configurações. Interessante, não ?
Para você ver o provisionamento completo, fiz o vagrant destroy da máquina anterior e vamos subi-la novamente:
$ vagrant up
Veja a saída do Puppet:
Agora, faça um vagrant ssh para acessar a máquina e utilize o comando ntpq -p para visualizar o status do Ntp:
Pela saída acima, os servidores a.ntp.br e b.ntp.br estão sendo utilizados, exatamente como desejávamos.
Se você acessar novamente a url http://localhost:8080/hello/ , o Apache deve estar sendo executado normalmente.
Antes de prosseguirmos, gostaria que você desse uma olhada no final do arquivo de configuração do ntp:
vagrant@desenvolvimento:~$ vi /etc/ntp.conf server a.ntp.br server b.ntp.br
As duas últimas linhas do arquivo possuem os endereços dos servidores a.ntp.br e b.ntp.br. Queria te mostrar agora que a idempotência está sendo respeitada ao provisionar a máquina novamente. Saia da máquina, mande o vagrant rodar o provisionamento novamente, acesse-a novamente e veja o final do arquivo /etc/ntp.conf:
$ vagrant up --provision $ vagrant ssh vagrant@desenvolvimento:~$ vi /etc/ntp.conf server a.ntp.br server b.ntp.br
Está vendo como as linhas com os endereços dos servidores ntp não foram adicionadas novamente ? A idempotência foi garantida pelo unless utilizado na resource declaratrion exec ‘ntp_config’.
Até o momento, já utilizamos alguns resource types (exec, package, service, file) nas resource declarations. Para uma lista completa dos resource types disponíveis na instalação padrão do Puppet, basta dar uma olhada aqui.
Como já estamos ficando com o manifesto mais complexos, vale a pena dar uma olhada no guia de estilo da linguagem utilizada pelo Puppet nos manifests. Algumas dicas: utilize dois espaços ao invés de tabs, faça comentários iniciando por #, utilize aspas simples, etc.
Você pode visualizar o código completo que desenvolvemos até agora aqui no meu Github.
Melhorando a legibilidade do manifest
Não sei se você lembra, mas quando criamos a box eunati/debian-jessie64-puppet5 no primeiro artigo sobre Puppet, já instalamos o módulo puppetlabs-stdlib. Ao utilizar um módulo, podemos ter acesso a novos resource types, novas classes (ainda não vimos o que são), novos facts (imagine que são variáveis globais pré-definidas), funções, etc.
No módulo stdlib existem vários resource types bem interessantes para uso junto ao Puppet. Um deles é o file_line, que nos permite adicionar ou remover linhas de arquivos. Ao invés de utilizar os comandos sed e o echo junto ao resource type exec, como fizemos no manifesto anterior para provisionamento do Ntp, podemos utilizar o file_line, que fica bem mais legível.
Dê uma olhada na nova versão do arquivo default.pp utilizando o file_line:
Agora, ao invés do antigo exec, temos três resource declarations com file_line. O primeiro remove os servidores que já vêm configurados no Ntp, o segundo adiciona o servidor a.ntp.br e o terceiro adiciona o b.ntp.br. Muito mais legível, não é ? E também não obriga que o profissional que está elaborando o manifest possua conhecimentos em sed e expressões regulares (embora eu considere tais conhecimentos fundamentais).
Ao fazer o vagrant up e depois o vagrant ssh, você observará que o arquivo de configuração do ntp (/etc/ntp.conf) está configurado da maneira que desejamos e que nosso manifest permanece idempotente (pode executar o provisionamento quantas vezes desejar).
Você pode visualizar o código completo utilizando o file_line aqui no meu Github.
Classes do Puppet
Sim, meus amigos, agora chegamos ao Grand Finale. Vamos utilizar as classes disponíveis nos módulos puppetlabs-docker e puppetlabs-ntp, também já instalados na box eunati/debian-jessie64-puppet5. Olha a definição de classes do Puppet:
Classes are named blocks of Puppet code that are stored in modules for later use and are not applied until they are invoked by name. Classes generally configure large or medium-sized chunks of functionality, such as all of the packages, config files, and services needed to run an application.
Ou seja, as classes nada mais são que conjuntos de resource declarations que podem ser reutilizados, inclusive com possibilidades de parametrização. Olha esses dois exemplos de declarações de classes que a documentação do Puppet nos apresenta (a primeira sem parâmetros e a segunda com um parâmetro):
Utilizando classes dos módulos puppetlabs-docker e puppetlabs-ntp
Ao invés de utilizar todas aquelas resource declarations para o provisionamento do Ntp, vamos utilizar a classe ntp do módulo puppetlabs-ntp, que já cuida de todo o provisionamento do Ntp em diversos sistemas operacionais. Tudo que temos que fazer é utilizar a classe e passar o parâmetro servers com a lista de servidores que desejamos utilizar. Dá uma olhada:
node 'desenvolvimento.eunati' {
class { 'ntp':
servers => [ 'a.ntp.br', 'b.ntp.br' ]
}
}
Só isso ? Yes!! O módulo abstrai toda a complexidade na classe ntp. Sacou que você também pode criar suas próprias classes, né ? A criação de uma classe e um módulo fica para um próximo artigo, mas é assim que você conseguirá reduzir a complexidade de seus manifests, deixando-os ainda mais legíveis. E claro, as classes e módulos são reutilizáveis. Coisa linda, né não ?

Classes e módulos: maravilhas!
E pra instalar o Docker ? Vamos utilizar a classe docker do módulo puppetlabs-docker, que também abstrai toda a instalação e configuração do Docker. O módulo em questão também possibilita gerenciar imagens e containers do Docker, facilitando bastante a integração com o Puppet. É um belo trabalho.
Se não for necessário passar parâmetros para uma classe do Puppet, podemos usar a palavra chave include ao invés da class. Veja como ficará nosso arquivo default.pp para provisionar o Ntp e o Docker Server na máquina virtual:
Apenas para subir o Docker Server, não precisamos passar nenhum parâmetro para a classe docker, por isso utilizamos o include.
Lembra que eu falei no início do artigo que adicionar resource declarations em uma node definition não é uma boa prática de acordo com a documentação do Puppet (o ideal é adicionar apenas variáveis e utilização de classes)? Pois pronto, agora nosso default.pp não possui mais resource declarations, mas apenas utilização de classes. Perfeito!
Tudo que precisamos fazer é subir a máquina virtual e checar se o Ntp e o Docker estão funcionando adequadamente:
E é isso aí! Ntp devidamente configurado e Docker executando um container corretamente!
Deu pra entender como os módulos do Puppet são poderosos ? Você percebeu que não precisei nem fazer o apt-get update ? Os módulos se encarregam disso, e olha que eu não precisei passar nenhum parâmetro indicando qual SO estou usando. No Puppet Forge você pode encontrar mais de 5.000 módulos disponíveis para o Puppet, dá uma fuçada por lá!
Você pode encontrar o código completo desse ambiente com Vagrant + Puppet + Docker aqui no meu Github.
Conclusão
Com este artigo, alcançamos um grande marco: integração entre Vagrant + Puppet + Docker.
Nos próximos artigos sobre ferramentas de apoio a times DevOps, todos os serviços que subirmos serão containers no Docker. O Docker será provisionado pelo Puppet e tudo isso será executado em uma máquina virtual gerenciada pelo Vagrant. Na sua produção, não sei se você utilizará o Vagrant ou outra solução para gerenciamento de virtualização, entretanto, para ambientes de desenvolvimento o Vagrant é fantástico!
Toda a infra do nosso ambiente de desenvolvimento é versionável (tudo no Github) e facilmente replicável. Infra como código! Esse último ambiente com Docker sobe aqui na minha máquina em apenas dois minutos. Pode brincar e quebrar o ambiente de desenvolvimento a vontade: é só esperar dois minutos e você estará com um ambiente novinho em folha! E se chegar um membro novo na equipe ? Passa o Git e pronto! Maravilha, né não ?

Infra como código!
Espero que você tenha gostado! Agradeço se você puder curtir e compartilhar esse artigo em suas redes sociais.
Próximos artigos:
Docker e containers: Fundamentos – DevOps Parte 6
Curta nossas páginas nas redes sociais para acompanhar novas postagens.
Em breve, mais conteúdos de qualidade para você aqui no Blog Eu na TI, o seu Blog sobre Tecnologia da Informação.
Um forte abraço e até mais.

Olá, sou Jonathan Maia, marido, pai, apaixonado por tecnologia, gestão e produtividade. Ocupo o cargo de Secretário de Tecnologia da Informação e Comunicação do Tribunal Regional do Trabalho do Ceará (TRT7) desde 2021, onde ingressei como servidor público federal (analista de TIC) no ano de 2010. Fui diretor da Divisão de Sistemas de TIC do TRT7 entre 2018 e 2020 e também tenho experiência prévia na Dataprev, Serpro e Ponto de Presença da Rede Nacional de Ensino e Pesquisa (RNP) no Ceará.
Graduado em ciências da computação pela Universidade Federal do Ceará e especialista em gerenciamento de projetos de TIC pela Universidade do Sul de Santa Catarina. Detentor das certificações em gestão e inovação: Project Management Professional © (PMP), Professional Scrum Master II © (PSM II), Professional Scrum Master I © (PSM I), Professional Scrum Product Owner I © (PSPO I), Kanban Management Professional © (KMP II), Certified Lean Inception Facilitator® (CLF), ISO 31000:2018 Risk Management Professional © e Project Thinking Essentials.
Desenvolvedor Full Stack, possuo experiência em diversas arquiteturas / plataformas de desenvolvimento. Já tive experiências profissionais em redes metropolitanas de alta velocidade (GigaFOR/RNP), business intelligence, desenvolvimento de sistemas, gestão de projetos e produtos, governança, etc. Experiência em dezenas de projetos com abordagens de gestão ágeis, híbridas e tradicionais, incluindo projeto com menção honrosa no Prêmio de Excelência em Governo Eletrônico (e-Gov).
Com dezenas de turmas de capacitação, oficinas ou palestras ministradas nas temáticas de gestão ágil, gestão de projetos, tecnologia, inovação e produtividade nas seguintes instituições: Conselho Superior da Justiça do Trabalho (CSJT), Tribunal de Justiça do Distrito Federal e Territórios (TJDFT), Tribunais Regionais do Trabalho do Ceará (TRT7), Pará e Amapá (TRT8), Sergipe (TRT20), Rio Grande do Norte (TRT21), Tribunais Regionais Eleitorais do Ceará (TRE-CE), Mato Grosso do Sul (TRE-MS) e da Bahia (TRE-BA), Justiça Federal em Sergipe (JF-SE), Justiça Federal no Ceará (JF-CE), Companhia Siderúrgica do Pecém (CSP), Instituto Federal do Ceará (IF-CE), Instituto Federal do Rio Grande do Norte (IF-RN), Banco do Nordeste do Brasil (BNB), Gagliardi (Mobil), Udemy, Companhia Cearense de Gás (CEGÁS), Agile Trends Gov, Project Management Institute (PMI-CE), Cagece, Faculdade Estácio e Associação de Gerenciamento de Projetos do Mato Grosso do Sul (AGPMS).
Comments
Excelente Artigo, aliás, assim como os outros quatro que compõem a série.
Muito obrigado, Waldemar! Um abraço.
Pingback: Docker e containers: Fundamentos - DevOps Parte 6 - Eu na TI
Pingback: Vagrant: Crie sua própria box e disponibilize-a na Vagrant Cloud - DevOps Parte 2 - Eu na TI
Pingback: Puppet: Instalação e fundamentos - DevOps Parte 4 - Eu na TI